공부 정리용 블로그입니다. 미숙한 실력으로 인해 표현이나 설명에서 많은 오류가 있을 수 있으니 참고 바랍니다 :)

Introduction
기본적인 카메라와 ray에 대한 개념이 있어야 이해하기 쉬울 것 같다. 이에 대한 내용은 CMU graphics 강의 정리에서 다루겠음.
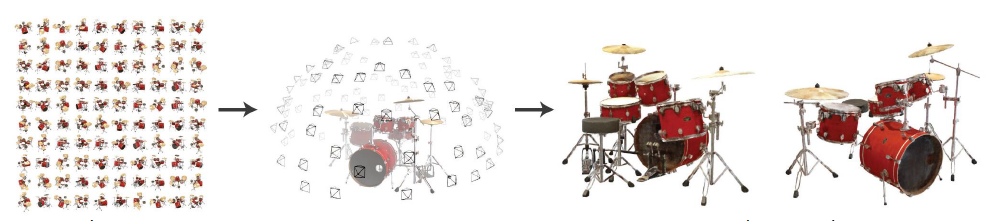
논문을 읽을 때 다음 사실을 알고 읽으면 더 편하게 이해가 된다. 해당 논문에서 설명하는 NeRF 모델은 하나의 scene에만 적용이 가능하다. 즉, 드럼 사진에 대해서 학습을 시킨 network는 다른 scene에는 적용을 시킬 수 없는 것이다. (필자는 하나의 network를 학습시키면 모든 scene에 적용할 수 있다고 생각하여 이해가 오래 걸렸다.)
NeRF가 어떤 모델인지 간단히 설명하면, 여러 위치에서 찍은 사진을 종합하여 데이터셋에는 없던 각도에서의 모습을 추측해서 보여주는 것이다.
Main Task

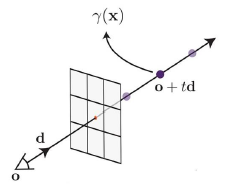
전체적인 흐름을 살펴보자.
- 특정 시점에서 특정 픽셀로 광선 (ray)를 발사한다.
- 해당 광선을 더 확장하고, 광선 위에서 임의의 점을 sampling 한다.
- 해당 점의 3D 좌표와 카메라 파라미터 정보를 MLP에 input
- MLP는 해당 점의 색상과 밀도를 output
- sampling 한 모든 점에 대해서 위 과정을 반복하고, 색상과 밀도 정보를 이용하여 최종 색상을 결정한다.
- predict 색상과 true 색상을 비교하여 loss 작성
Methods
Sampling

deterministic 샘플링은 고정된 좌표를 매 iteration마다 뽑는 것이다. 즉, 고정된 점에 대해서만 학습이 진행된다는 단점이 존재한다.

stratified 샘플링은 앞선 샘플링의 단점을 보완하고자 제안된 방법이다. 고정된 구간이 있고, 해당 구간 내에서는 매 iteration마다 랜덤하게 샘플링을 진행한다. 모든 부분에 대해서 학습이 진행된다는 차이점이 존재한다.
MLP
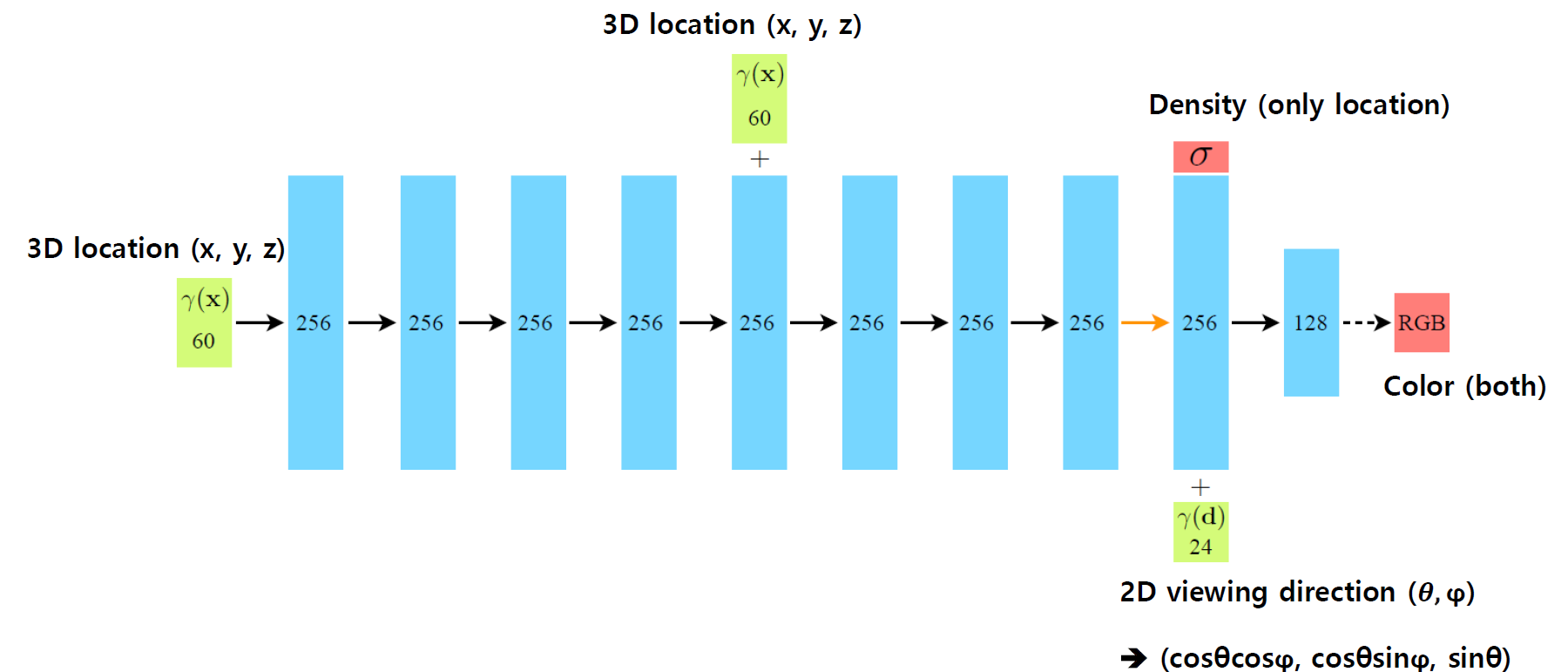
모델 구조는 mlp 구조로 간단하다. 샘플링된 점의 3D 좌표 값과 skip connection으로 density를 구하고, 여기에 viewing direction 3d vector (3d Cartesian unit vector)를 추가하여 color를 얻는다.
색상을 구하기 위해 viewing direction을 이용하는 이유는 non-Lambertian 효과를 반영하기 위해서이다. Lambertian efftect는 모든 시선 방향에서 동일한 색상을 띠는 것을 의미한다.
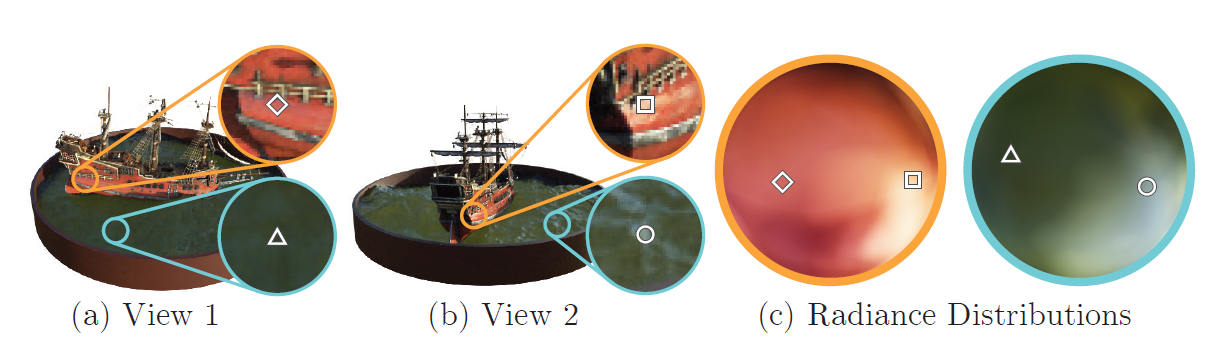
위 그림에서 (a) 방향과 (b) 방향에서 바라본 동일한 위치의 색상이 다름을 확인할 수 있다.
이렇게 구한 각 샘플 포인트들에 대하여, 최종 픽셀을 결정하는 방법은 다음과 같다.
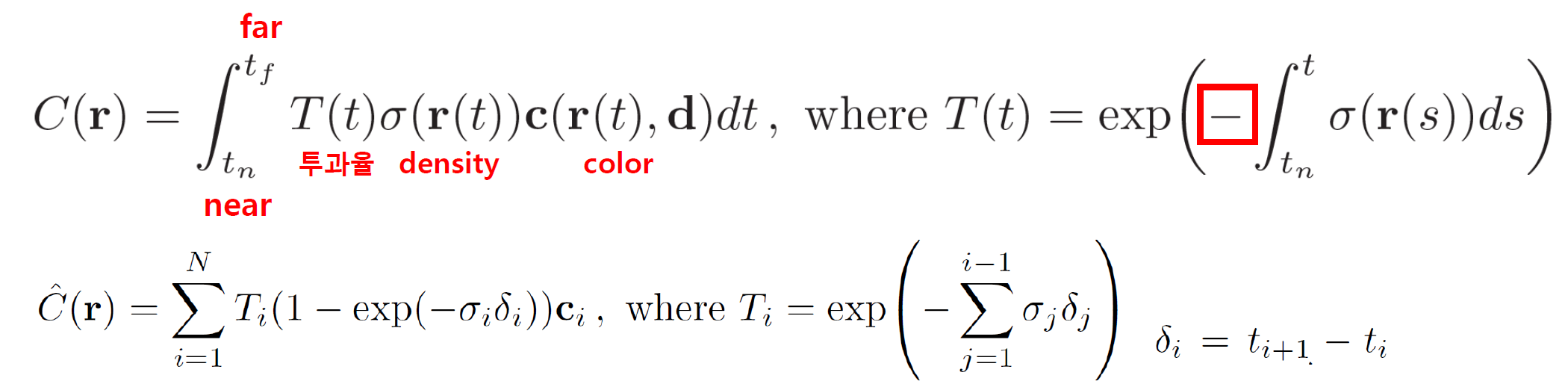
물체가 존재할 범위 (near~far)까지 투과율 x 밀도 x 색상 값을 적분한다. 이때, 투과율은 밀도와 반비례한다. 논문에서 말하길, 밀도는 물체가 존재할 확률이다. 즉, 물체가 존재할 확률이 높으면 해당 지점의 투과율은 낮을 것이다.
위 적분 식은 모든 좌표에 대해서 실행되는 식이다. 그러나 실제로 모든 점에 대해서 하나하나 할 순 없다. 이를 위해 위 논문에서는 구분구적법을 사용한다. 밀도와 투과율이 반비례함을 이용하여 밀도를 (1-투과율) 로 표현했다고 생각해볼 수 있다.
Problem

모델 자체는 간단하다고 느껴진다. 다만 이렇게 해서 나온 결과는 high-frequency를 잡아내지 못한다.
(high-frequency는 디테일한 부분, 경계부분이라고 생각하면 좋다.)
선행 논문에서 deep network는 lower frequency를 학습하는 방향으로 편향되어서 진행된다고 한다.
이를 개선하기 위해 논문에서는 positional encoding과 hierarchical sampling을 제안한다.
Optimizing
Positional Encoding
mlp의 경우, input으로 비슷한 값을 넣으면 비슷한 값을 output한다는 생각에서 나온 것이다. 그렇다면, input의 차이가 크게 만들면 문제가 해결되지 않을까? 즉, input의 차원을 높여서 input 간의 차이를 키우고 원래는 발견하지 못한 특징이 반영되도록 수정하는 과정이다.

input (x, y, z)은 L = 10으로 20차원의 벡터가 된다. 이 과정을 각 좌표에 대해서 진행하므로 3 x 20 = 60 차원의 벡터가 된다.
input (3d direction vector)은 같은 방식으로 L = 4 이므로 3 x 8 = 24 차원의 벡터가 된다. mlp 파트의 architecture 사진을 보면 input이 각각 60, 24로 표현되어 있는 것을 확인할 수 있다.
Hierarchical sampling
기존의 샘플링은 물체의 여부를 확인하지 않고, 랜덤으로 뽑아 빈 공간 or 불필요한 공간까지 샘플링하였다. 논문에서는 이를 수정하여 유의미한 곳을 효율적으로 샘플링하는 방법을 제안한다.
Coarse network 와 Fine network 2개의 과정으로 진행된다. (network가 아닌 과정으로 이해하면 편하다.)
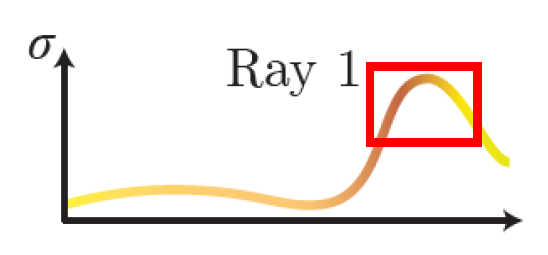
앞선 과정에서 구한 밀도 분포를 그래프로 나타내고, 여기에서 밀도가 높은 부분을 추가적으로 샘플링하겠다는 것이다.
과정을 나타내면 다음과 같다.
- stratified sampling (Nc개)를 mlp에 넣어 밀도 분포 (coarse network)
- 밀도가 높은 쪽에서 sampling (Nf개) 추가 진행
- Nc + Nf 샘플링 포인트를 다시 mlp에 넣어 최종 density와 color output (fine network)

coasre network와 true color의 차이, fine network와 true color의 차이로 Loss function을 정의한다.
Evaluation

다른 모델을 능가하는 성능을 보인다. (평가지표와 다른 모델에 대한 지식이 없어 추후 추가 예정)

여기서 주목할 포인트는 positional encoding과 hierarchical sampling로 인한 성능 차이이다.
Conclusion
- NeRF는 기존 CNN base model을 능가하는 간단한 mlp라는 점에서 효율적이다.
- 최적화를 위해 coarse & fine network로 구성된 샘플링 기법을 제안하였다.
- 하나의 이미지에 대해 학습한 모델의 크기가 작다. ( NeRF 5MB vs LLFF 15GB)
- 다만, 학습하는데 너무 많은 시간이 걸린다. (1~2일)
초기 NeRF의 학습 시간 문제를 해결하는 여러 NeRF가 있으며 기회가 된다면 instant NeRF에 다루어보겠다.
'3D Vision' 카테고리의 다른 글
| [논문 Review] Putting NeRF on a Diet: Semantically Consistent Few-Shot View Synthesis (0) | 2024.08.26 |
|---|---|
| [논문 review] Zero-Shot Text-Guided Object Generation with Dream Fields (0) | 2024.08.22 |
| [논문 review] Text2Mesh: Text-Driven Neural Stylization for Meshes (0) | 2024.08.08 |
| [논문 review] Human Motion Diffusion Model (0) | 2024.07.27 |
| [논문 review] SMPL: A Skinned Multi-Person Linear Model (0) | 2024.07.02 |