공부 정리용 블로그입니다. 미숙한 실력으로 인해 표현이나 설명에서 많은 오류가 있을 수 있으니 참고 바랍니다 :)

이번 시간에는 Text2Mesh 모델에 대해서 다루어보겠다. CLIP을 활용하여 text를 입력 받아 mesh에 styling한다.
Introduction
이전에도 text를 입력받아 스타일링하는 task가 존재했었다. 예를 들어, Text2Shape (2018.03)의 경우 text를 입력 받아 그에 맞는 3D shape을 출력한다.
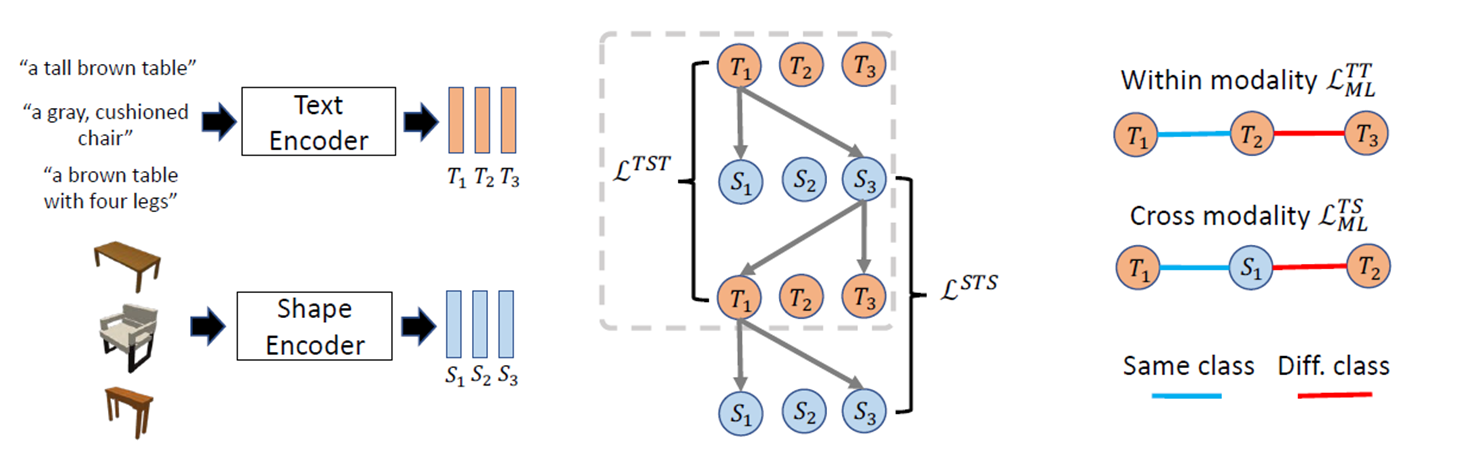
(정확한 방법론은 이해하지 못했지만 전체적인 흐름을 보자면) text와 shape을 각각 인코딩한 후, T와 S의 유사도를 구하고 이어서 해당 S와 T의 유사도를 구하는 방식으로 round-trip probability (TST)를 구한다. 같은 방식으로 STS도 구하여 서로 다른 데이터 유형 (text, shape)을 joint embedding한다.
이처럼 이전 작업은 joint embedding이 복잡하다는 문제점을 가지고 있다. 그러나 CLIP (2021.02)의 등장으로 text와 image의 joint embedding이 간단하게 처리됨으로써 Text2Mesh (2021.12)가 등장하였다.
Methods

전체적인 흐름은 다음과 같다.
1. 기본 mesh (content)와 text prompt를 입력 받는다.
2. MLPs를 통과하여 색상 (color)와 geometric detail (displacement)를 이용하여 stylized mesh ( Ms)를 얻는다.
3. Ms를 특정 view에서 2D projection하고 해당 image와 text 간의 CLIP 유사도 측정을 통해 loss 생성한다.
자세한 과정을 살펴보기 전에 간단히 input mesh의 형태를 알아보자.
vertices V (Rn x 3), faces F ({1,…. n}m x 3) 즉, m 개의 정점과 m개의 면으로 이루어져있다.

기본 mesh 중 alien mesh의 경우, 34,217개의 정점과 68,430개의 면으로 이루어져있다.
Neural Style Field (NSF)
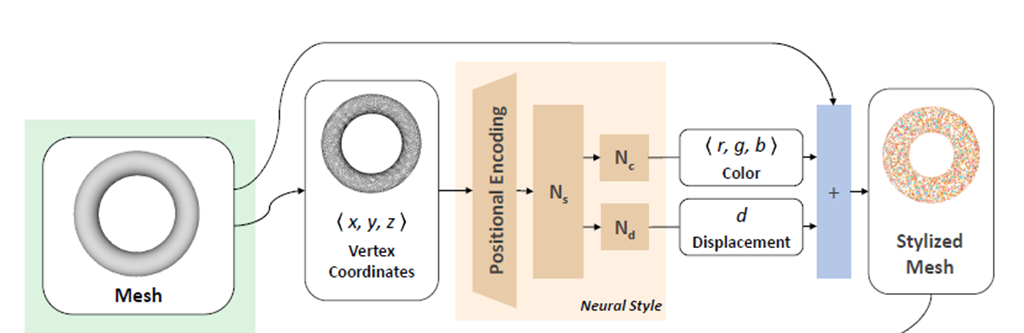
1. input으로 주어진 기본 mesh를 unit bounding box에 맞게 normalize (좌표값을 평균값으로 빼고, 등등...)
2. high-frequency를 위해 positional encoding

NeRF paper에서도 등장했던 positional encoding은 3차원 좌표를 더 높은 차원으로 만들어주는 방법이다. encoding 방법을 NeRF와 조금 다르지만 모두 입력 차원을 높여 higher frequency를 이루고자 한다.
여기서 시그마는 하이퍼 파라미터로 뒤에서도 보겠지만, 값이 클수록 frequency가 증가한다.
3. input each MLPs
positional encoding을 거친 값들이 Ns의 input으로 들어가고, 각각 Nc, Nd로 나누어져서 처리된다. 이렇게 해서 나온 color 값 (0~1 rgb)은 정점의 색상이 되고, displacement에서 나온 스칼라 값 (-0.1 ~ +0.1)은 기본 mesh의 형태를 text에 맞게 조금 변형하는데에 사용된다.

displacement 값이 어떻게 사용되는지 궁금할 수 있다. 일단 기본 input mesh는 계속 고정되는 것이 아니라 text에 맞게 texture를 반영하며 변형된다. 그러나 너무 많은 변형이 일어나지 않게 -0.1~+0.1 사이의 값으로 제한한다.
학습을 통해 변형된 mesh의 정점은 기존 정점에 해당 정점의 법선 벡터 방향으로의 d (displacement)를 더하여 구해지게 된다.
이러한 과정으로 stylized mesh를 생성할 수 있다. 추가로 여기에 색상은 반영을 하지 않은 displacement-only mesh (M displ)도 같이 생성한다.
Augmentation
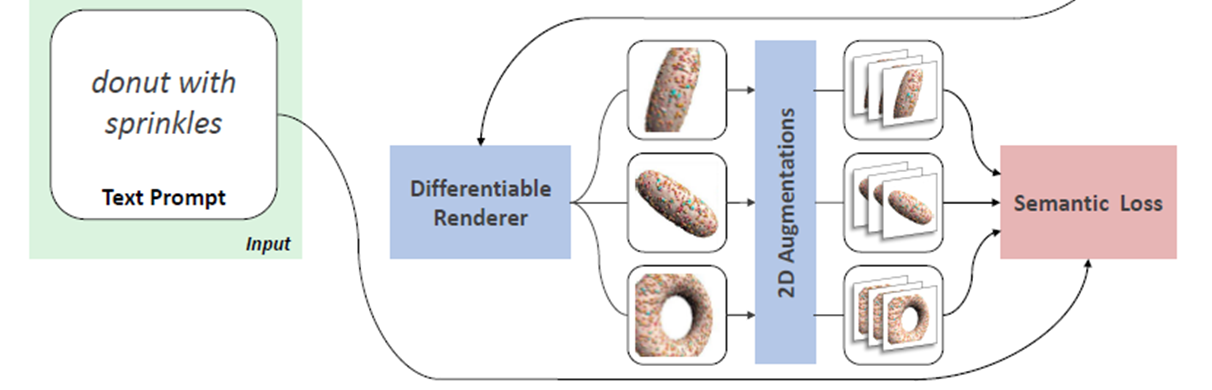
생성된 stylized mesh를 augmentation 해야한다.
1. 사전에 정의된 anchor view를 중심으로 총 n개의 view를 설정한다. (논문 n=5)
2. 해당 view에서 2D projection하여 구해진 image를 augmentation (global & local aug)한다.
3. 각 augmentation과 text 간의 loss 를 구한다.
추가적으로 anchor view를 구하는 방법을 설명하고자 한다. 어느 한 물체를 중심으로 하는 가상의 구가 있을 때, 일정한 간격으로 view를 설정한다. 그리고 각 view에서 projection된 image와 text 간의 유사도를 계산하여 가장 높은 유사도를 보이는 view를 anchor view라고 한다.
이 anchor view를 중심으로 하는 분산 pi/4 정규 분포에서 랜덤으로 n개의 view를 샘플링하는 방식으로 진행된다.
Loss
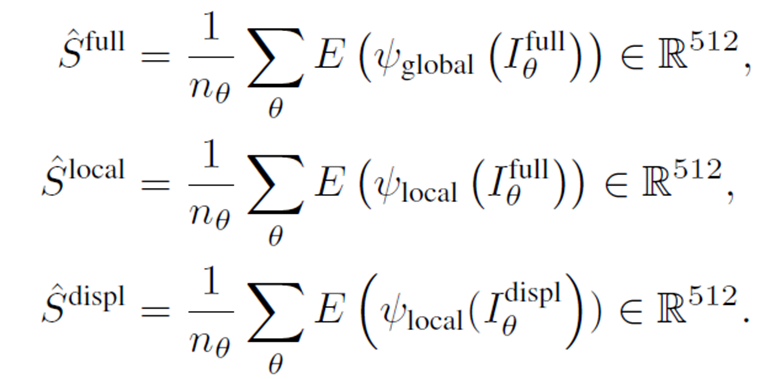
먼저 average embedding을 구해야한다.
Sfull은 Ms mesh를 2D projection 시킨 후, global augmentation을 통해 만들어진 average embedding이다.
Slocal의 경우에는 local augmentation이며, Sdispl은 Mdispl을 local aug하여 구해진다.
(자세한 설명은 논문의 3.2 파트 참고)

이렇게 구한 average embedding과 text embedding과의 코사인 유사도를 계산하여 loss를 형성하게 된다. code에서는 코사인 유사도에 마이너스 (-)를 붙인다.
Experiments
Ablation study

-net: MLPs 삭제
-aug: augmentation 삭제
-FFN: positional encoding 삭제
-crop: local augmentation에서 crop 삭제
-displ: displacement-only mesh 삭제
-3D: input 3d mesh 삭제
-3D는 input content를 주지 않은 경우이며, 결과물이 우리가 원하는 것과는 거리가 멀어보인다. 그럼에도 점수가 높은 이유는 CLIP은 데이터의 3D 형태를 보고 판단하는 것이 아닌 2D image만 봐서 이러한 결과가 나왔다고 설명한다.
Positional encoding

앞에서 봤던 것처럼, positional encoding의 sigma를 증가시키면 higher-frequency한 결과물이 나오게 된다.
User Study
해당 task의 선행 작업이 존재하지 않아 user study를 사용한 것으로 보인다. 비교 모델은 VQGAN-CLIP을 확장하여 사용하였다.

VQGAN-CLIP의 결과물을 보면 우리가 원하는 모습과는 거리가 멀다. 우리의 방법은 content라는 틀에 text의 특성을 반영하여 texture를 수정하는 것이다. 그래서 전체적인 틀에서 많이 벗어나지 않으면서 내용을 반영하여 자연스러운 결과물을 보이는 반면, VQGAN-CLIP은 text의 내용을 직접 생성하려고 하다 보니깐 여러 사물이 합쳐져서 부자연스러운 결과물을 보인다고 생각한다.
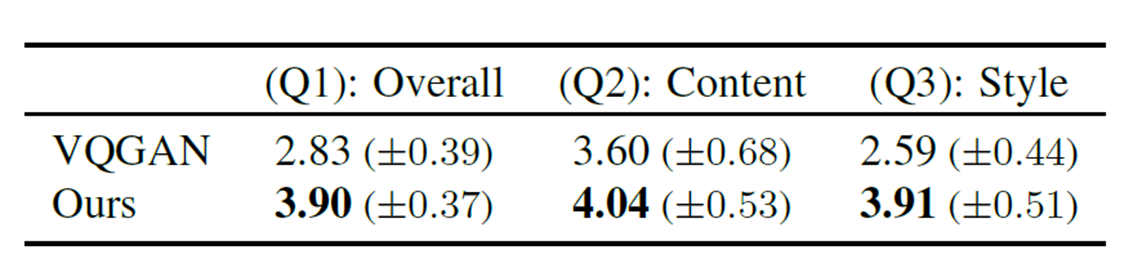
Q1: 결과물이 얼마나 자연스러운가? (1~5)
Q2: 처음의 input mesh와 얼마나 매칭되는가? (1~5)
Q3: 결과물이 target style에 얼마나 부합하는가? (1~5)
3개의 모든 질문에 대해서 Text2Mesh가 더 높은 성능을 보였다.
Image Target

target으로 text 대신 image를 주었을 때에도 좋은 성능을 보였다.
Conclusions
input mesh와 prompt 내용 간의 관련이 없으면 input mesh를 많이 변형시키는 문제점이 생긴다.

이를 방지하기 위해서는 prompt를 줄 때 input mesh의 특성을 다시 언급해줘야한다는 한계점을 가지고 있다.
또한 CLIP bias를 조심해야한다.

간호사라는 prompt를 주었을 때, 특정 성별이나 인종으로 편향되어 output할 수 있다는 점을 고려해서 사용해야한다.
Text2Mesh는 CLIP 모델의 개발로 joint embedding이 가능하게 되어 등장하였으며, 다양한 Text-to-3D tasks에 활용될 수 있다는 장점을 가진다.