공부 정리용 블로그입니다. 미숙한 실력으로 인해 표현이나 설명에서 많은 오류가 있을 수 있으니 참고 바랍니다 :)

지난 시간에 다루었던 Text2Mesh와 같이 text를 이용한 3D 생성 재미를 느껴서 거의 비슷한 시기에 나온 Dream Fields를 공부하게 되었다.
Introduction
Text2Mesh의 경우, input mesh를 주고, text를 이용하여 이를 스타일링하는 모델이었다. 그러다보니 mesh를 input으로 주어야한다는 불편한 점이 존재했다. 이번 Dream Fields는 처음부터 text를 이용하여 3D 객체를 생성한다는 차이점이 존재한다.
또한 3D dataset은 생성에 많은 비용이 들 supervised learning의 어려움이 있다. 이를 CLIP을 활용한 zero-shot learning으로 해결을 최초로 시도했다. CLIP이 나온지 얼마 되지 않아 대부분의 논문에서 CLIP을 사용하였는데, 이후 본 논문의 task를 diffusion을 활용한 DreamFusion이라는 논문도 나와 이것도 추후에 업로드할 예정이다.
Background
Dream Fields는 NeRF를 이용하여 3D 객체를 만들고, 이를 특정 pose에서 랜더링하여 image-text score를 계산하는 모델이다. 그러다 보니 NeRF에 대해 알고 읽으면 수월하게 읽을 수 있을 것이다.
NeRF
NeRF에 대해 간단히 이야기해보면,

3D 공간의 3차원 좌표를 입력으로 넣고 해당 좌표의 color와 density를 구하는 MLP가 있다. 특정 pose에서 ray를 쏘고, 해당 ray 위의 점의 특성 (color, density)를 합쳐 최종 픽셀의 색을 구하게 된다. 모든 픽셀에 대해 위 과정을 반복하여 특정 pose에서의 이미지를 얻고, GT와 MSE loss를 활용하여 MLP를 optimize하는 방식이다.
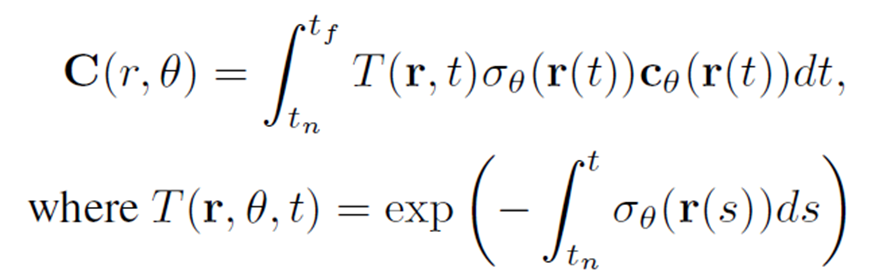
Transmittance라는 누적 투과율 (T)와 density, color를 위의 식에 넣어 최종 color를 결정하게 된다.
Image-Text models
NeRF를 이용하여 랜더링된 이미지와 text prompt 간의 비교를 위해 vision encoder와 text encoder를 이용한다. 서로 다른 modality의 비교를 위해서는 같은 공간으로의 임베딩이 필요하다. 여러 방법이 있겠지만, 본 논문에서는 CLIP을 활용한다.
image와 text 임베딩 벡터 크기를 각각 1로 설정하고 이를 내적하여 (cosine similarity) scalar score를 구하여 image와 text를 비교할 수 있다.
Methods
background 내용만으로 dream fields의 방식을 알 수 있지만, 여기에 추가적인 디테일을 첨가하였다.
먼저, 기존 NeRF의 경우 viewing direction을 고려하여 시각에 따른 색 변화를 나타내었다.

논문에서는 이를 반영하는 것이 장점을 가지지 않는다고 판단하고 이를 없애 파라미터 값은 낮추지 않았을까 예상한다.
전체적인 pipeline을 살펴보면,
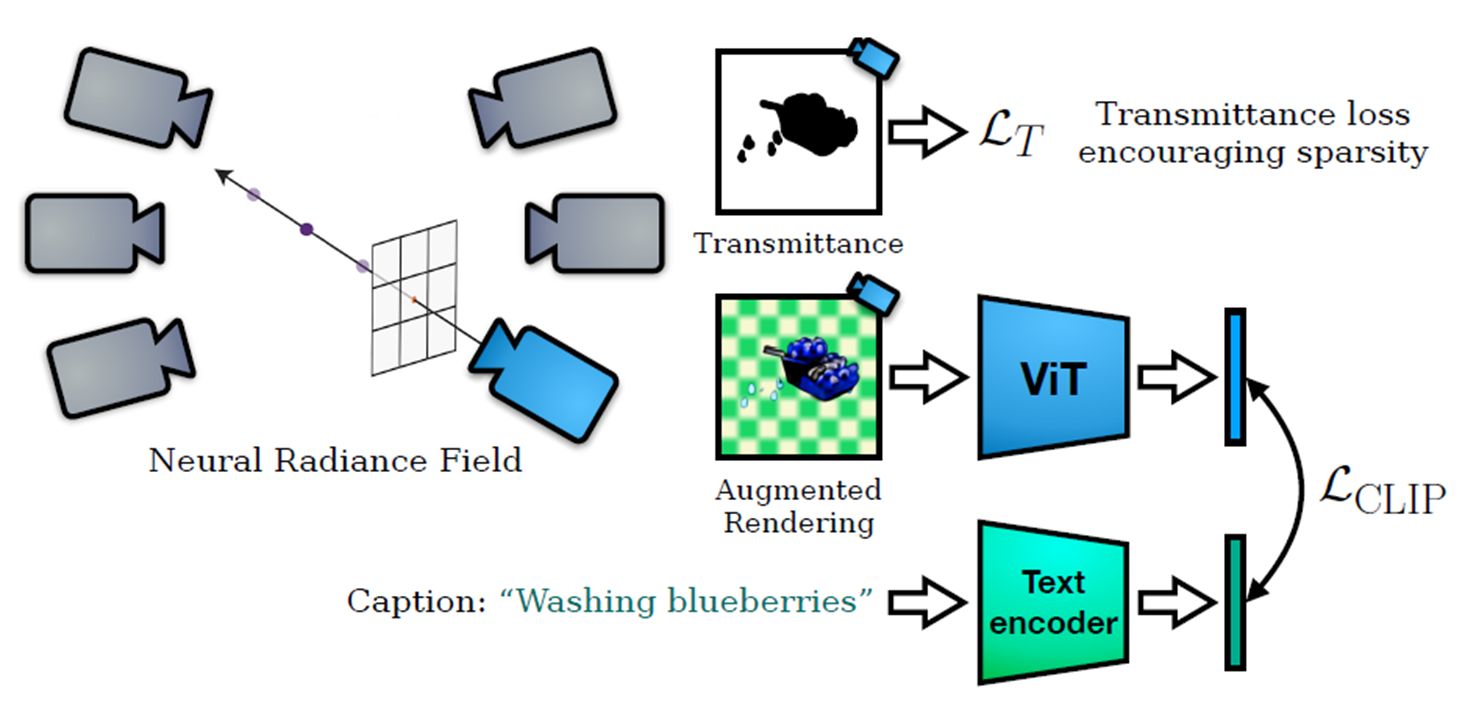
NeRF를 활용하여 이미지를 랜더링하고 image와 text 각각을 인코딩하여 CLIP Loss를 구한다.

background에서 봤던 것과 같은 형태이며, loss를 minimize하여 유사도를 maximize하는 방향으로 학습이 진행되게 된다.
이렇게 단순하면 좋겠지만, 이는 near-fields artifacts, spurious density 현상을 발생시킨다.
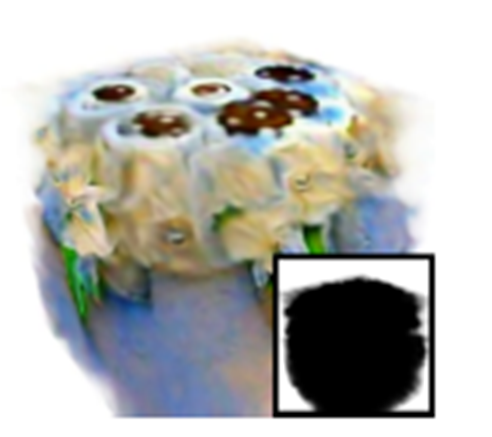
위 이미지와 같이 물체가 없는 배경까지 밀도가 있다고 판단하는 현상을 spurious density라고 한다. (near-fields artifacts은 이미지가 없어 상상에 맡긴다.. 가까이에 있는 물체에 어색한 모습이 나타난다는 현상인 것 같다.)
문제를 해결하기 위해 transmittance loss를 추가한다. 평균 transmittance를 target 값까지 maximize하여 투명도를 조절하겠다는 의도이다.
target값을 40%에서 88%까지 여러 iteration을 거쳐 조금씩 증가시킨다.

LT값을 보면, mean 값이 t보다 크게 되면 t가 나오게 되어 gradient가 0이라 학습이 진행되지 않고, mean값이 나오게 되면 mean을 증가시키는 방향으로 학습이 진행되게 된다.
그.런.데. 여전히 문제가 발생한다고 한다. 이는 바로 객체와 배경 간의 경계가 명확하지 않다는 것이다. 즉, 객체와 배경의 구분을 잘하지 못한다. 이를 해결하고자 background augmentation을 이용한다.
원래는 배경을 흰색 또는 검정색으로 설정하였다. 그러나 배경을 노이즈, 특정 패턴, 체크 패턴 등의 방법으로 다양하게 학습하여 경계를 학습한다.
Experiments
background augmentation 영향

위쪽과 아래쪽은 background augmentation 유무에 따른 결과값의 차이이다. 적용하지 않았을 때는 배경 부분에도 밀도가 존재하고, 경계가 뚜렷하지 않은 반면, 적용한 후에는 확실히 뚜렷해진 것을 볼 수 있다.

두 개의 loss를 서로 곱했을 떄, 서로 더했을 때 각각의 성능을 비교하기도 한다. 수치적인 성능 (R-Precision)은 똑같았다. 그러나 두 개의 loss를 곱했을 때는 식이 더 복잡해지고, non-convexity 문제가 있어 쉬운 optimize를 위해 additive 방식을 이용했다.
각 method의 영향

method를 하나씩 추가해보았을 때, 성능의 변호를 보여주는 실험이다. 여기서 관심있게 본 것은 positional encoding을 적용했을 때의 성능 변화이다.
higher-frequency를 위해 이를 적용하지만 text와의 유사도 측면에서는 성능에 영향을 주지 못한다. 즉, semantic한 변화를 주지 못한 것인데, 더 디테일하게 객체를 묘사한다고 해서 사자처럼 보이지 않았던 것이 갑자기 사자로 보이는 것은 아니기에 이러한 결과가 나왔을 것이라고 생각한다. 만약 text prompt를 조금 더 디테일하게 주었다면 성능 향상을 보였을지 궁금하다.
Target Transmittance 영향

Transmittance loss에서도 target 투명도를 높게 설명하면 할수록 더 뚜렷한, 쓸데없는 밀도 표시가 없어지는 것을 확인할 수 있다.
Pose sampling 영향
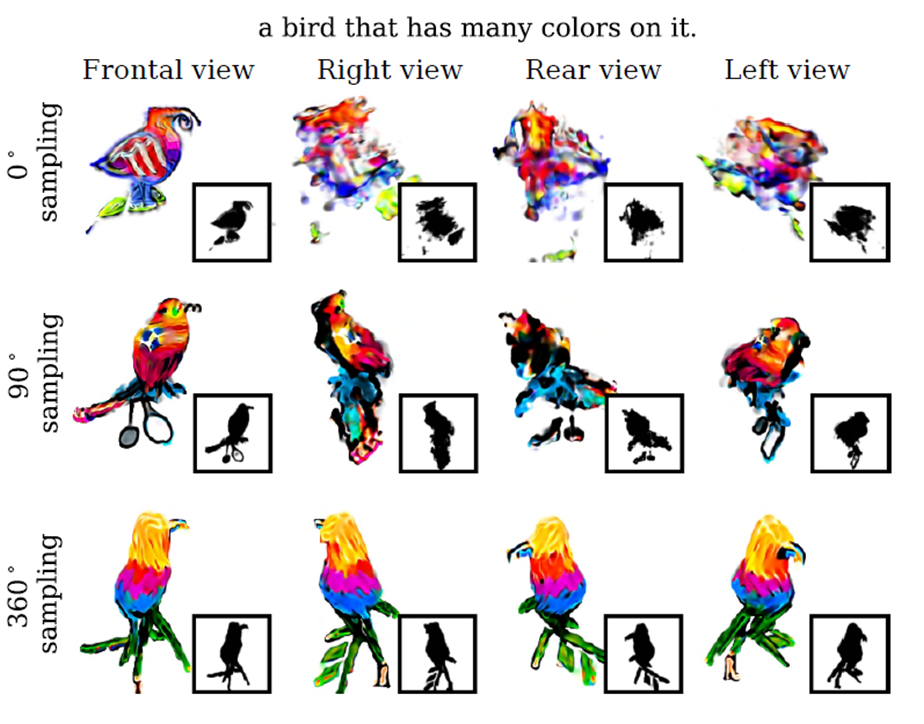
카메라 pose를 sampling하는 반경을 변화시키면서 결과물을 확인하는 실험이다. 작은 반경에서 실험을 진행하면 그만큼 학습이 되지 않는 영역이 많다. 반면, 360도에서 샘플링을 진행하게 되면 모든 측면이 잘 학습된 것을 확인할 수 있다.
Styling

마지막으로 이건 스타일링을 얼마나 잘하는지 보여주는 실험으로, 아보카도를 입은 armchair를 그려주는 방식으로 기본 물체에 스타일을 적용시키는 것이다.
(이것은 Text2Mesh에서 진행한 task와 일치하는 것으로, 거의 동일한 시기에 나온 만큼 text2mesh를 견제하는 것이 아닌가하는 개인적인 생각..)
Conclusion
dream fields도 한계점이 있는데, 먼저 모든 카메라 pose에서 동일한 text를 사용한다는 것이다. 이렇게 진행하다보니 여러 측면에서 동일한 패턴이 나오는 현상이 발생한다고 한다.
또한 각 method의 영향을 관찰한 실험에서 GT 데이터에 대한 성능이 그리 높지 않다. 이를 통해 아직은 text-image 모델의 성능이 충분히 좋지 않아 이를 개선할 필요가 있다.
이 논문이 나오고 디퓨전이 발표되면서 그것을 적용한 dreamfusion을 읽어보고 앞선 한계점을 극복할 수 있었는지 확인해보면 좋을 것 같다.