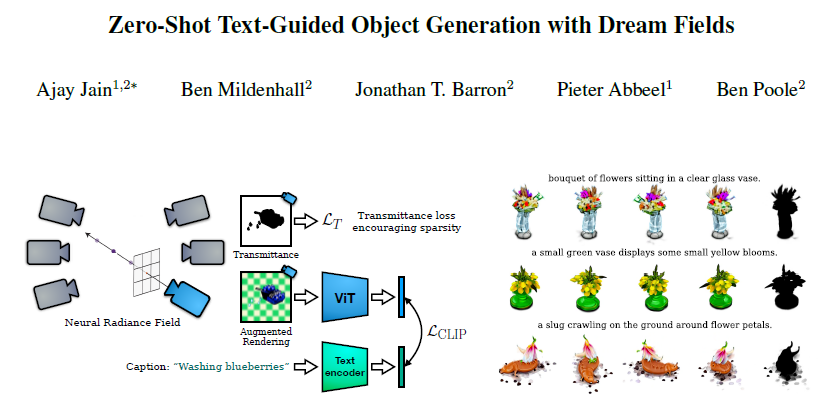
공부 정리용 블로그입니다. 미숙한 실력으로 인해 표현이나 설명에서 많은 오류가 있을 수 있으니 참고 바랍니다 :)지난 시간에 다루었던 Text2Mesh와 같이 text를 이용한 3D 생성 재미를 느껴서 거의 비슷한 시기에 나온 Dream Fields를 공부하게 되었다. IntroductionText2Mesh의 경우, input mesh를 주고, text를 이용하여 이를 스타일링하는 모델이었다. 그러다보니 mesh를 input으로 주어야한다는 불편한 점이 존재했다. 이번 Dream Fields는 처음부터 text를 이용하여 3D 객체를 생성한다는 차이점이 존재한다. 또한 3D dataset은 생성에 많은 비용이 들 supervised learning의 어려움이 있다. 이를 CLIP을 활용한 zero-sho..